First of all, hi and welcome to the new official litesim blog, in keeping with the "new approach", this is being hosted externally on blogspot.
And now for something completely different......
Reliability - how you do itOne problem with Second Life™ that many people complain about is reliability - or rather the lack of it. Due to the rapid development cycle of Linden Lab™ there are often changes made that break things, and worse sometimes bugs can cause simulator crashes, problems with the garbage collection algorithm can cause inventory loss and more.....
.....and opensim is worse.
This is a major problem for virtual worlds in general and not just Second Life, but there is one issue in Second Life (and its clones) that make it worse, and that problem is the issue of 1-to-1 mapping on too many aspects of the service.
One server per region, one client connection per region in which a user's avatar is visible or which a user can see or otherwise interact with. There's even evidence that the backend maps one inventory server to each user, and they share their inventory shard amongst multiple users. Group chat for the longest time has suffered similar issues.
The problem with this approach is simple: one server goes down, it takes down (in the case of simulators) 4-8 regions, or it takes down multiple users' whole inventory, or it takes down a whole group's ability to chat until things are repaired.
Single points of failure are bad, everyone in the industry knows that and the standard practice in critical cases is to ensure you always have a backup - a plan B so to speak. If server A goes offline and destroys all data on the harddrive somehow, you switch to server B and use the most recent backup dump.
There are problems with this approach too though - how old is the backup? how much data have your users/residents lost? how equal is the backup system in terms of computational power and resources?
Worse still, on SL-like systems, there's a contention on the backend constantly, and that contention is always getting worse with more users, more regions, more content.
Don't take my word for it though, see these scary looking graphs:
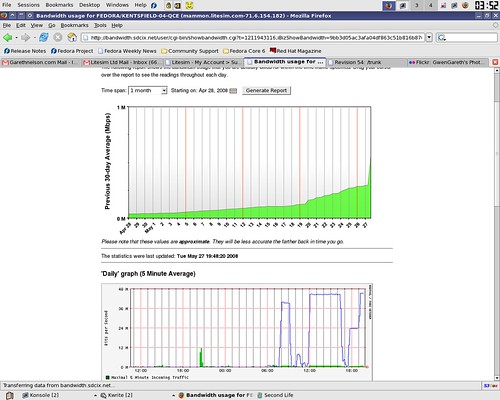

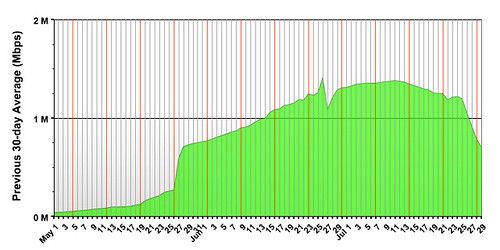
The above graphs should be quite familiar to anyone who's ever maintained any service that requires a heavily-loaded backend. If you've done so and they aren't familiar you either already know the new approach litesim will be using or you just haven't maintained something that got such attention.
The scariest part is that this wasn't even a large setup - the above graphs are for what is by all definitions a small virtual worlds provider, and one experimenting with
SL for dialup users at that. Still, very very quickly bandwidth usage shot up, as did the demand for disk space as users rushed to create more and more content.
What was the problem?
Contention
Although it's easy (and even cheap - thanks carinet, you guys rock) to setup a big bunch of servers, they need to interact - and in a virtual world they need to interact with one set of data, one set of resources.
In the OGS (Open Grid Services - the grid services that tie together opensim grid installations) system, we use UGAIM (used to be UGAS, but I digress):
- User Server - handles user logins, authentication etc, also listens for logouts
- Grid server - like a login server for simulators, keeps track of what region goes where, authenticates simulator servers, handles grid info requests and map block requests
- Asset server - user content
- Inventory server - user inventory, heavily coupled with the user server (or at least was in the period the graphs above originate from)
- Messaging server - handles a few misc bits of user presence
On top of this, to implement the interop in litesim, we had the node controller daemon. This daemon, written in python, needed at least one instance per subgrid and handled migration of user accounts between subgrids, handled the OGP proxy interface and "reported back" to the website to give users a log of where they've recently been and where they're currently logged into. Once an hour, all the node controllers would be polled and the latest information placed into metaverse.xml in a function humorously called "build_teh_metaverse()".
Spot the issue yet?
Look harder - although each simulator acts on a separate scenegraph and separate simulation, they all need to talk to this entity we call "the grid", and the underlying database.
"the grid" in some cases lived on a single server, with the simulators occupying other servers. lsmainland, the main grid lived on multiple servers, but that was the exception as the busiest of all the subgrids.
So, we have 2 points of failure here:
The grid daemons
The database
Since some of the grid daemons were stateful, they could not be load balanced, meaning that once a client node (whether that client is a user's viewer or another part of the system) talked to server A, it had to keep talking to server A and could not talk to server B.
The most dramatic example is the simulators, here everything is about state - state that is extremely complex and is managed by a system coded from the ground up with the assumption that only 1 server will ever be interacting with that state - in some cases there are even race conditions due to bad assumptions about only 1 thread interacting with the world state.
Some of the most exotic and difficult to track down bugs arise due to this, but bugs are par the course for any software system and i'm not here to talk about them (this side of the singularity, imperfect humans do all the coding).
What i'd like to talk about here is what happens when one server crashes. Servers can crash in numerous ways, either physical servers have actual hardware failure (I recall one night spent without sleep while trying to salvage a harddrive that overheated, this is not a fun job to do remotely), or the daemons running on them have bugs that cause them to lock up or otherwise stop doing their job.
Unless you are the nietzschian uber-mensch or a singularity-level AI, your code will have bugs and any hardware you build will be vulnerable to physical problems. Simulator servers will always crash, data centers will always have fires, or even
get raided by law enforcement and shut down.
The only thing you can do in this scenario is to work around the crash, and to do that in such a way that you can provide the illusion to end users that no crash occurred.
Doing this requires taking into account the following modes of failure:
- Hardware failure
- Software bugs, glitches and flaws
- Human failure
- Socio-legal issues
Point 1 can be overcome simply - get more hardware. But you have an issue here, how do you ensure that the new hardware maintains identical state? How do you make the switchover so quick that it isn't even noticed?
The answer is that you don't switch over - switching over suggests that you have a migration period while you switch off the first server and move to the second one - not even possible if the first server has gone down and taken your data with it. You can't rely on backups to preserve
identical data either, unless you're backing up every clock cycle - in which case you shouldn't be wasting your time reading this blog and should be out making a fortune on such advanced technology.
Rather than switch over, you ensure that every single byte that comes in gets processed by at least 2 servers, such that both server A and server B have the same state and there is no need to migrate. If server A goes down, you stop sending bytes to it and tell your users to do the same thing, probably by dropping it from DNS.
Point 2 is more tricky depending on the type of glitch. Obviously if you run the same code on both server A and server B then any glitch occurring on server A given the same bytes will also occur on server B.
Sadly there is no real answer to this one at the core besides using normal software engineering practices such as unit testing, code review, strong functional style etc. What you can do is reduce the risks that come with such glitches by keeping very regular backups.
Beyond a certain threshold of complexity, it becomes impossible to guarantee that a system will behave well - this is a limit of the human minds of the people who build such systems, not a limit of the systems themselves (computers blindly do what we tell them). Since we're all merely human though, we need to plan in ahead for how much we'll screw up on more complex systems, the only guarantees we can offer therefore are that screwups can be repaired after the fact.
Prevention is better than cure, but sometimes prevention is not possible - the cure in this scenario is therefore to return to your backups. Any bug or glitch in the software that causes a bad state to arise needs to be corrected and the old "good" state returned. To offer solid guarantees to your users, you need to detect such glitches before the bad state corrupts the resulting simulation any further.
There are 2 approaches here, one very hi-tech and expensive, the other remarkably simple. I'll start with the simple one:
Keep lots of backups, pay attention to user problem reports, guarantee your users that bugs will be responded to and that you will keep hold of any data for X number of iterations of the simulation back. This could be as simple as saying that you will keep a full week's worth of state and guaranteeing that any corruption of user data will be resolved by reverting the state and offering a refund for paid services.
Pretty simple, and it's what the industry generally has to do.
The other approach is rather more advanced. You run your simulation at 2 speeds - normal and "turbo". For each instance of the simulation you run one at normal speed and one in turbo. In turbo mode, you watch the simulation ahead of time, giving it the exact same input as the normal mode and watch the outcome - essentially predicting the future.
Although this seems impossible, it's actually rather simple, if you consider how much time elapses between a user giving input and some form of output being sent out. Speed up this small gap for turbo mode, or slow it down in normal mode, and you have a reliable means to predict "1 step ahead" for every single event in the simulation. If you do this well you'll be able to have a view of the future state before it occurs in the normal speed simulation, and for some types of interaction you could have a pretty large window in which to either live code a bug fix or grab a backup of the current state.
Doing this requires you have staff watching things though, and the window of opportunity shrinks smaller and smaller with each user - heavy user traffic means lots of input events, compressing the window of opportunity for your state prediction. So, doing it this way leads to the not so surprising situation that more users means you get worse results.
A hybrid approach is to keep small snapshots (as diffs) of each and every state change, by doing this you can ask a complaining user where the simulation went bad and rewind to that precise point.
Point 3 is not all that different from point 2, and so much of the same solutions apply, but in all cases one thing that must happen is for the state data to be available on all servers.
Point 4 is one which requires a few none-technical solutions alongside the technical solutions to avoid the possibility of falling foul of civil or criminal law and having things shutdown. This can happen even to those who are completely innocent as a side-effect of other activities, and the following are suitable countermeasures (note, I am not a lawyer and this is not legal advice):
- Distribute mirrors of everything across different nations with wildly different legal systems, preferably with different languages
- Ignore intimidation tactics that are not backed by law, and where it is backed by law only do the minimal required to comply
- Where there is a choice between removing one piece of content and bringing down the whole service and this is a guarantee, remove that piece of content but relocate it ASAP to a foreign nation
On the technical side, registering domains on different registrars, having DNS RR records and distributed server farms with revolving IPs can help to ensure that service remains operational even if one nation in which you host servers becomes hostile.
The other thing to avoid at all costs is vendor lockin, this may be done for temporary convenience but can come at the cost of utter destruction later on. Avoiding this one requires avoiding proprietary software platforms or any external service you are not capable of rebuilding a compatible version of. One practical example is Google App Engine, the litesim.com website is being partially hosted on this platform but much work has gone into ensuring that at a moment's notice it can be relocated to any other hosting provider - right down to abstracting the database support and avoiding some of the more helpful features google offer.
GPLed software also helps here - if your entire stack is copylefted, then those who would "embrace and extend" it to lock you in hold no power.
So, that's how you make crashes invisible to users, but how do you make resource depletion invisible to users and scrap contention?
Answer - purely functional programming in erlang
By programming in a purely functional style (avoiding side effects) you can at a moment's notice cut off a chunk of code and throw it onto another server, you can also load balance at will and run the numbers to see how much metal you need to support X users with solid guarantees on service quality.
This is precisely how the new litesim is being built, and that is why release will be a long way off - getting things right is important, host your virtual worlds with litesim and get solid mathematics backing up the service's performance metrics, even if data centers are literally burning down and being raided.
What should be very obvious is what this does for your free speech and peace of mind.
Labels: erlang, functional style, litesim, qos, reliability
